tags:
- OS
- Thread and Concurrency
第一课 Thread of Execution
1.0 Thread Motivations
没有线程的时候,在一个 HTTP 的服务器上,每一个客户端的连接都将对应一个进程的创建。在高并发的场景下,每秒都可能有成百上千个客户端需要建立与服务器的链接,频繁创建并销毁进程带来的开销可能是服务器不可承受之重。此外,进程间通信也会为系统带来不小的开销。
那么,我们是否有更好地方法来降低系统开销,实现一种机制来避免进程复制或切换所给我们带来的系统开销呢?在剖析进程时,我们发现进程中有很多部件,而执行程序是在栈区中执行的。为了减少进程操作开销,人们将进程中负责执行程序的部分称为线程,线程所需要的资源都共享进程的。从而,我们可以在服务器进程中,用多线程的方式同时服务多个客户端,减少了进程开销。
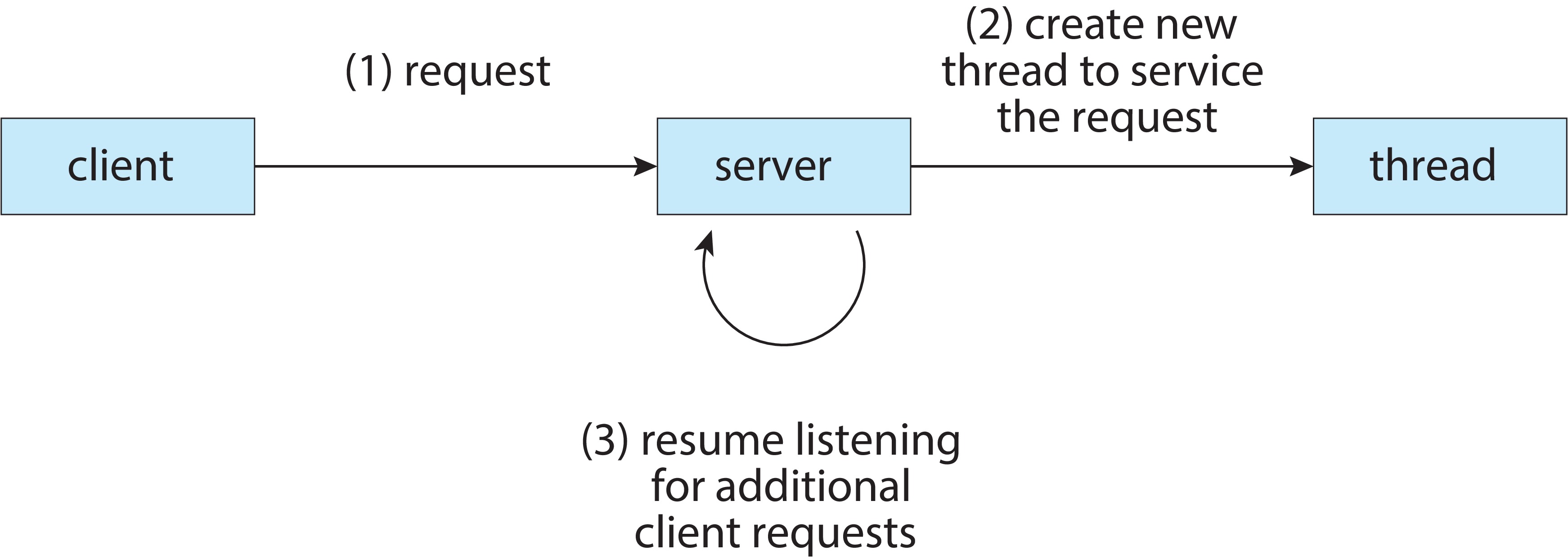
线程是执行线程的简写,它是一系列顺序任务流,这些任务流可被CPU调度。由于线程的调度和操作相比进程系统开销要小很多,所以现在的操作系统使用线程作为CPU调度的基本单位,即线程是最小的可调度单位。而进程,作为资源管理的基本单位,可以被看作是线程的容器。
1.1 Thread Possessions
为了让这个最小的可调度单位能够正常的工作,我们需要给线程分配必要的资源。每个线程都需要独立的 TCB ,包括寄存器组、PC寄存器和堆栈指针等。此外,还需要给每个线程分配栈空间以确保能够调度执行。这些线程会共享同一个进程中的代码段、数据段和文件等资源。由于线程的轻量,我们也称其为轻量级进程(Light-weight process),这样的轻量型为减少系统开销帮了不少忙。

由于线程所占用的资源很少,所以创建和销毁线程要比进程快得多(10×),而且上下文切换的时间也更快。又因为所有线程共享进程的资源,所以同一进程中线程间交流并不需要IPC。要使程序运行起来,一个进程就至少需要有一个线程,叫做主线程(main thread)。
此外,线程间共享进程资源还为我们带来另一个好处——高缓存命中率(关于缓存亲和性的内容将在CPU调度阶段中学习到)。由于线程的轻量型,线程切换通常不需要将一些上下文重新加载到缓存中,所以缓存命中率高。
1.2 TCB and Thread States
1.2.1 Thread Control Block
线程和进程一样有各种各样的状态,操作系统为了对线程进行管理和调度,在线程创建的时候会为线程创建一个TCB来存放线程执行相关的信息。TCB数据结构中的数据通常包括:
- 线程ID:用于唯一标识系统内的线程;
- 线程状态:如运行、等待、就绪等;
- 寄存器内容:保存线程的上下文信息,确保线程能够恢复执行;
- 优先级:用于调度策略;
- 线程特定的数据:每个线程私有的数据区;
- 指向PCB的指针;
- 指向不同内存区域的指针:text,data,heap and stack;
- 资源信息指针。
- ...
为了使线程执行相独立,线程的栈空间和上下文信息是线程独享的,与其他线程相独立。虽然线程TCB中有指向资源的指针,但这些资源都是共享的,线程并不作为资源的管理者。
在Linux中,进程和线程都使用task_struct数据结构来描述它们的状态和信息。但同一进程内的线程间共享进程内的地址空间和资源。我们也有线程组的概念,同一进程内的主线程和其他线程组成一个线程组,组号tgid即为主线程的线程标识符。
1.2.2 Thread States
和进程一样,每个独立的线程也都有自己的状态。我们之前介绍的进程模型有七种状态,线程也有自己的五态模型。由于线程并不是资源的调度单位,我们不用考虑线程在内存上的换入和换出,因此在线程模型中不会看到挂起态。线程的五态有:new、ready、running、waiting、terminate。
线程的状态和进程的状态息息相关,如果进程因等待I/O操作或其他资源而阻塞,那么所有线程也会进入阻塞状态。当进程处于就绪状态时,虽然它的线程已经准备好运行,但进程没有被调度到CPU上,因此所有线程暂时不能使用CPU资源。这就是进程被称为最基本的资源调度单位的原因。
如果所有的线程都被阻塞,而进程处在就绪态呢?由与进程的运行需要依托至少一个线程的可运行状态,所有即使进程能够获取资源也不可以执行任何任务。
1.3 Thread Context Switch
线程上下文切换是操作系统从一个线程的执行状态切换到另一个线程的执行状态的过程。这个过程的过程和进程上下文切换的过程类似。与进程的上下文切换相比,线程的上下文信息更小,所以切换效率更高。
1.3.1 Thread Switching Inside a Process
在同一进程下,由于线程之间共享进程资源,其上下文切换通常不涉及存储块的交换,所以线程切换的局部性更好(保留缓存内容,可能不需要刷新MMU)。
1.3.2 Thread Switching Between Processes
我们刚才比较同一进程内的线程切换,由于进程内的线程共享了大部分进程资源,因而开销相对较低。而跨进程的线程切换则不太一样了。由于跨进程的线程没有共享的进程资源,而且进程与进程之间的内存空间和安全环境的完全隔离,所以跨进程间的线程切换的系统开销要大得多。
1.3.x Kernel Heap
在阶段-5,我们接触到了内核栈,我们用内核栈来存储中断上下文。那问题来了,进程的上下文 PCB 和线程的上下文 TCB 在哪里存储呢(task_struct in Linux)?它们在内核堆中存储。内核堆和用户进程的堆空间一样,是一种动态内核数据结构。
我们没有接触 CPU 调度的内容。简单起见,你需要理解——当线程切换时,内核需要负责保存当前线程的 TCB 并恢复调度线程的 TCB 。由于这一过程在内核中进行,所以硬件和系统会先将中断上下文保存到内核栈中。然后操作系统保存剩余的上下文(TCB)到内核堆,调度程序选择一个线程,恢复其 TCB 并通过 iret 返回用户态或内核态执行。
1.4 Lighter but Stronger
线程的这种轻量型可以带给我们很多好处,但也能够给程序的执行带去不少的烦恼。下面,我们将比较线程和进程在各个方面上的不同,然我们得以对两者有更好的理解。
1.4.1 Lighter is Lighter
在它们的创建方式上,我们讨论进程fork()的创建方式。在POSIX thread库中,线程通过pthread_create()来创建。由于进程是资源调度的基本单位,所以在进程创建的过程中,除了创建一个主线程之外,还要将父进程的所有资源映像拷贝到进程自己的内存空间中。相比之下,线程不需要进行资源的完整复制,而是共享同一进程的资源,因而线程的创建更小。
由于线程共享进程中的资源,因而线程的内存开销和切换开销要小很多。你可以将进程和线程理解为大石头和小石头,操作系统搬小石头肯定更加地容易。在数据的共享上,进程会使用繁琐的IPC机制,在同一进程内的线程不需要考虑这些,因为它们的资源是共享的。
1.4.2 Lighter can Indeed Cause Fires
事事都有其两面性,看过线程光鲜亮丽的一部分,我们接下来学习线程阴暗的一面。相比进程之间彼此隔离,由于线程间资源共享可能导致一系列问题。比如不当的调度导致的资源竞和死锁问题。我们说线程栈是独立的,但不像进程空间那样隔离。理论上,一个线程可能访问另一个线程的栈空间,这是非常危险的。可能导致程序的崩溃。
1.4.3 Thread-Local Storage
在前面,我们说多个线程可能属于一个进程,这些线程共享进程中的数据。这种数据共享是多线程编程带给我们的一个好处。但在某些情况下,每个线程可能需要自己的某些数据副本。我们将这种数据称为线程局部存储。
一个线程的TLS仅对这一个线程可见,这破坏了一定的共享性,但会带来很多好处(比如避免可能导致的资源竞争和死锁问题)。为了在线程的生存周期内可用,TLS通常声明为静态的。在C语言和C++中,可以使用 __thread (编译器提供)或 thread_local (C++11)来声明TLS变量。
如果我们想为一个线程分配一个唯一的标识符,我们可以这样声明:
#include <stdio.h>
#include <pthread.h>
__thread int threadID = 0;
void* printThreadID(void* arg) {
threadID = (int)(long)arg;
printf("Thread ID: %d\n", threadID);
return NULL;
}
int main() {
pthread_t t1, t2, t3;
pthread_create(&t1, NULL, printThreadID, (void*)(long)1);
pthread_create(&t2, NULL, printThreadID, (void*)(long)2);
pthread_create(&t3, NULL, printThreadID, (void*)(long)3);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
return 0;
}
#include <iostream>
#include <thread>
thread_local int threadID = 0;
void printThreadID(int id) {
threadID = id;
std::cout << "Thread ID: " << threadID << std::endl;
}
int main() {
std::thread t1(printThreadID, 1);
std::thread t2(printThreadID, 2);
std::thread t3(printThreadID, 3);
t1.join();
t2.join();
t3.join();
return 0;
}
1.5 Multi-threading Models
1.5.1 Thread Types
以上,我们了解了内核级线程(kernel level threads),内核级线程是由操作系统直接管理的线程。每个内核级的线程都有自己的TLB,线程的数据结构由操作系统内核管理,存储在内核空间。除了内核级线程,我们还有用户级线程(user-level threads) 的概念。
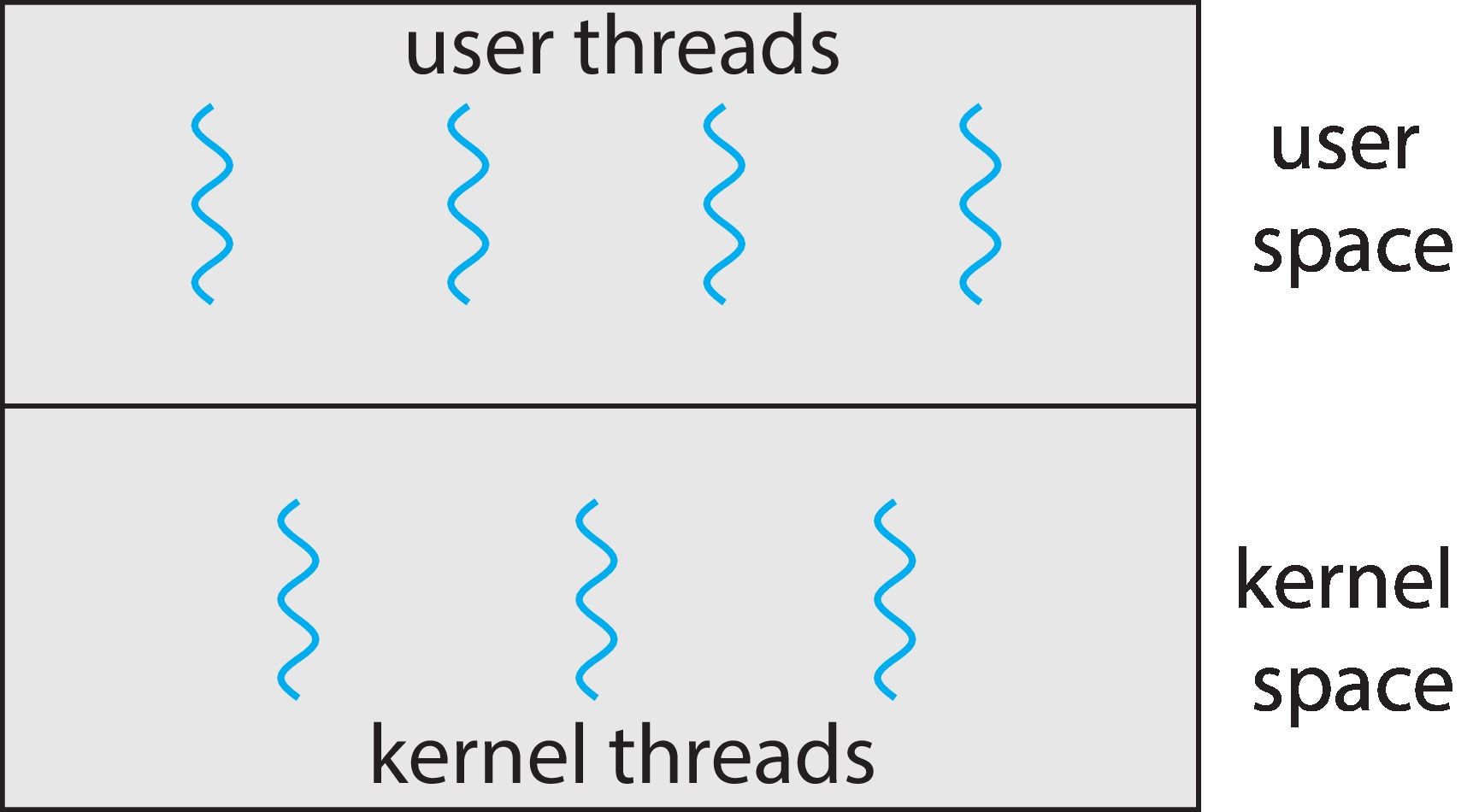
内核级线程和用户级线程都有自己的线程资源(栈、上下文信息等),但是内核级线程是被操作系统管理的,而用户级线程被用户空间的程序所管理,内核并不需要知晓用户机进程的存在。
1.5.1 李逵和李鬼
用户级线程的突然出现让我们猝不及防,用户级线程是对内核级线程的模拟。在前面学习的线程中,我们说(内核级)线程是CPU基本的调度单位,这里的线程实际上就是内核级线程。用户级线程是在用户空间创建的,也就是说内核空间中并不会创建相关的TLB。TLB相当于线程的操纵句柄,因而系统没有办法对用户级线程进行调度。
由于内核并不会记录ULTs的资源和上下文,所以ULTs并不能参与CPU的调度。ULTs的运行建立在运行在CPU的KLTs之上。虽然看上去ULTs好像并不大方便高效,但这种线程事实上能够带给我们许多好处,如:ULTs的操作都是在用户态进行的,所以ULTs的系统调用和上下文切换的开销可以非常低。ULTs的创建、切换等操作并不需要内核的帮助,速度可以相较KLTs快很多。
但是这种线程的缺点也显而易见,多个ULTs运行在一个KLT上,没有实际线程的并发,性能可能并不够好。如果一个KLT对应多个ULTs,每个ULT可能只会获得1/n的线程性能。下面,我们将介绍三种用户级线程和内核级线程的设计模型:多对一模型、一对一模型、多对多模型。
1.5.2 Many-to-One Model
多对一模型中,一个KLT上要支持多个ULTs的执行。我们前面提到过,ULTs的切换开销很低,所以这种模型中的上下文切换非常快。但由于这种模型只有一个KLT,这就意味着一时间在这些ULTs只能有一个在CPU上执行。即使在多核处理器上,并行在这种模型上是不可能实现的。
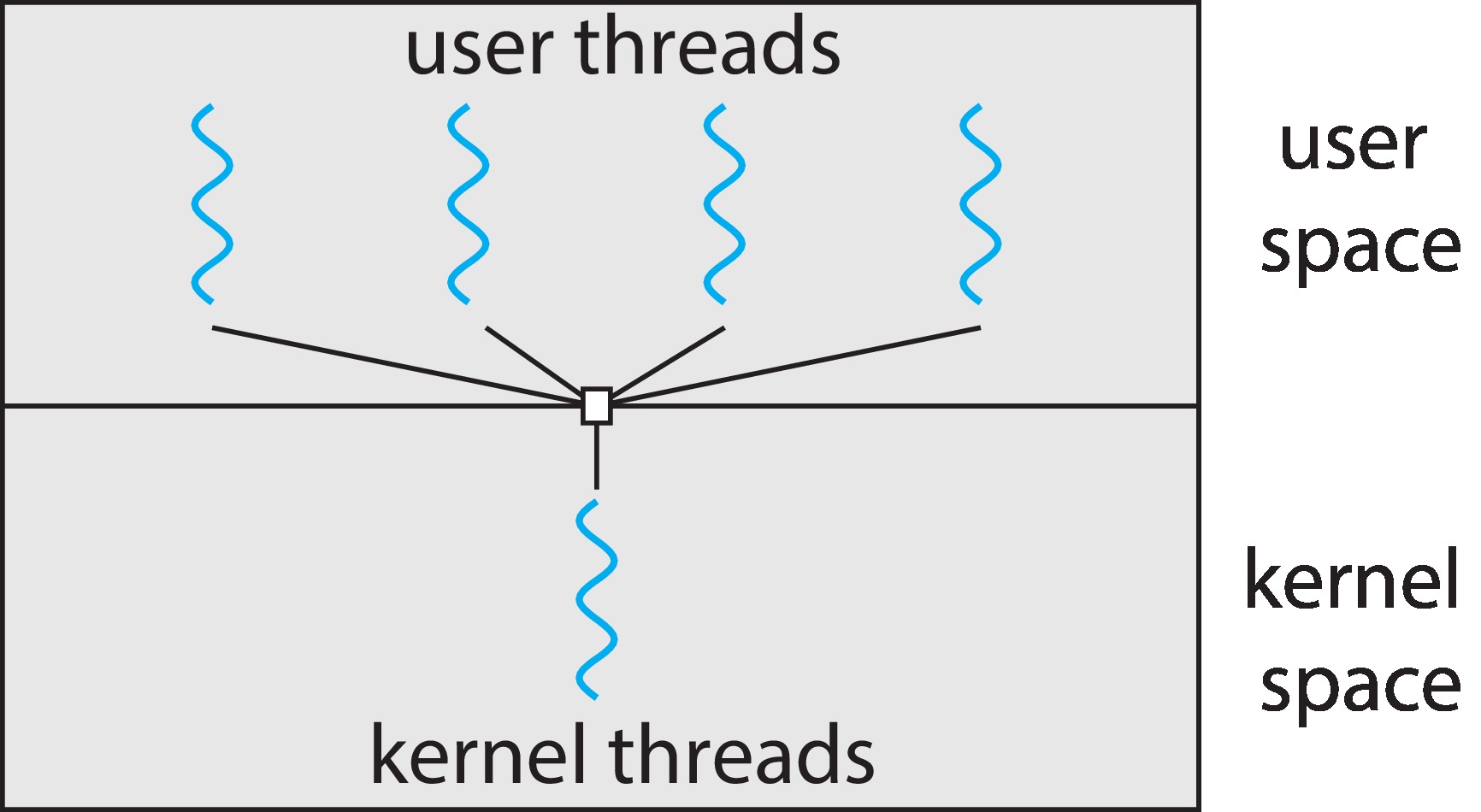
而且,如果某个时刻其中一个ULT调用了阻塞的系统调用(使用I/O),那么唯一的那个内核级线程将会阻塞。进而,整个进程会被阻塞,剩下的那些用户级线程就也随之阻塞。一个ULT的阻塞导致了所有ULTs的阻塞。
1.5.3 One-to-One Model
在一对一模型中,每个ULT都对应着一个KLT,每个ULT事实上变成了一个独立的调度单位(因为ULT的线程操作就对应着KLT的线程操作)。这种模型和我们学习的线程是对应的。使用一对一模型后,我们就不必担心一个ULT的阻塞导致整个进程阻塞的事件发生。而且,使用一对一模型后,这些ULTs可以在多处理器上并发地运行。

由于这种模型的一一对应,我们实际上失去了ULTs给我们带来的好处。我们不能再享受到多用户级线程带来的快速上下文切换速度;当你创建一个用户级线程后,你还需要使用系统调用来创建另一个支持ULT的系统级线程。而且,我们失去了线程调度的灵活性,因为所有的调度将在内核的调度器下完成。
尽管有这么些缺点,现在的许多操作系统仍然采用一对一的模型。一方面这种模型较好实现,而且多核处理器也能够有较好的性能来支持庞大数量的内核级线程数量。
1.5.4 Many-to-Many Model
在多对多模型上,N 个用户级线程被小于或等于N的内核级线程所支持。相比上两种模型,多对多模型更加灵活,性能看上去也更好。在多对多模型中,ULT 可以不再绑定到特定的 KLT 上了。我们可以在用户级的线程库中实现一些机制,使得当某个 KLT 被阻塞,其余的ULT可以迁移到其他的 KLTs 上。当然,这就意味着可怜的 cache 命中率。
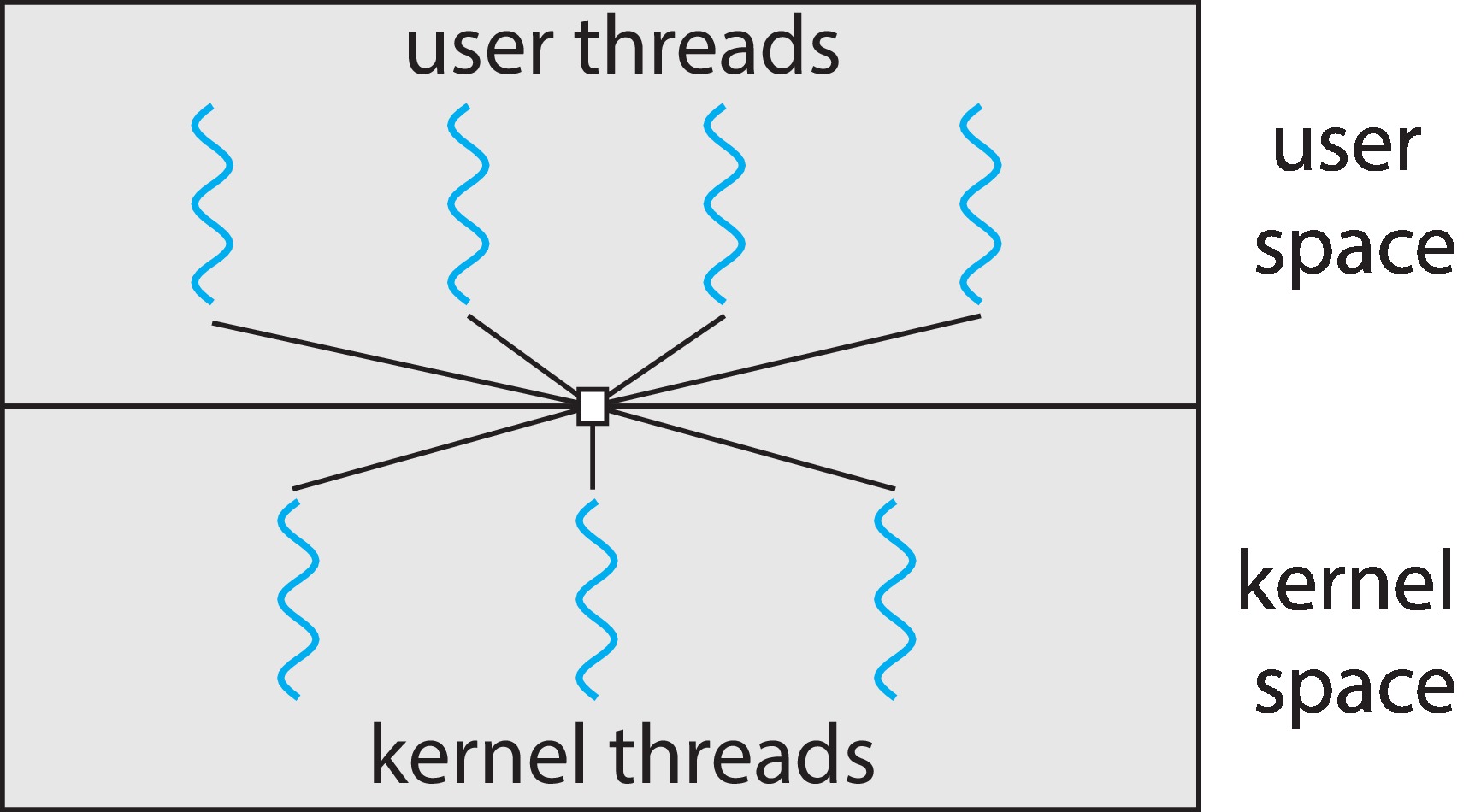
红利吃尽代价总是要偿还的,这种模型实现起来更为复杂,而且用户级线程的线程库调度的效率可能并不如内核调度更加有效,还有更大的开发和维护成本。FreeBSD5支持M:N的线程模型,到 FreeBSD7 时默认只使用 1:1 模型,并从 FreeBSD8 完全放弃了M:N模型。
1.5.5 Two-Level Model
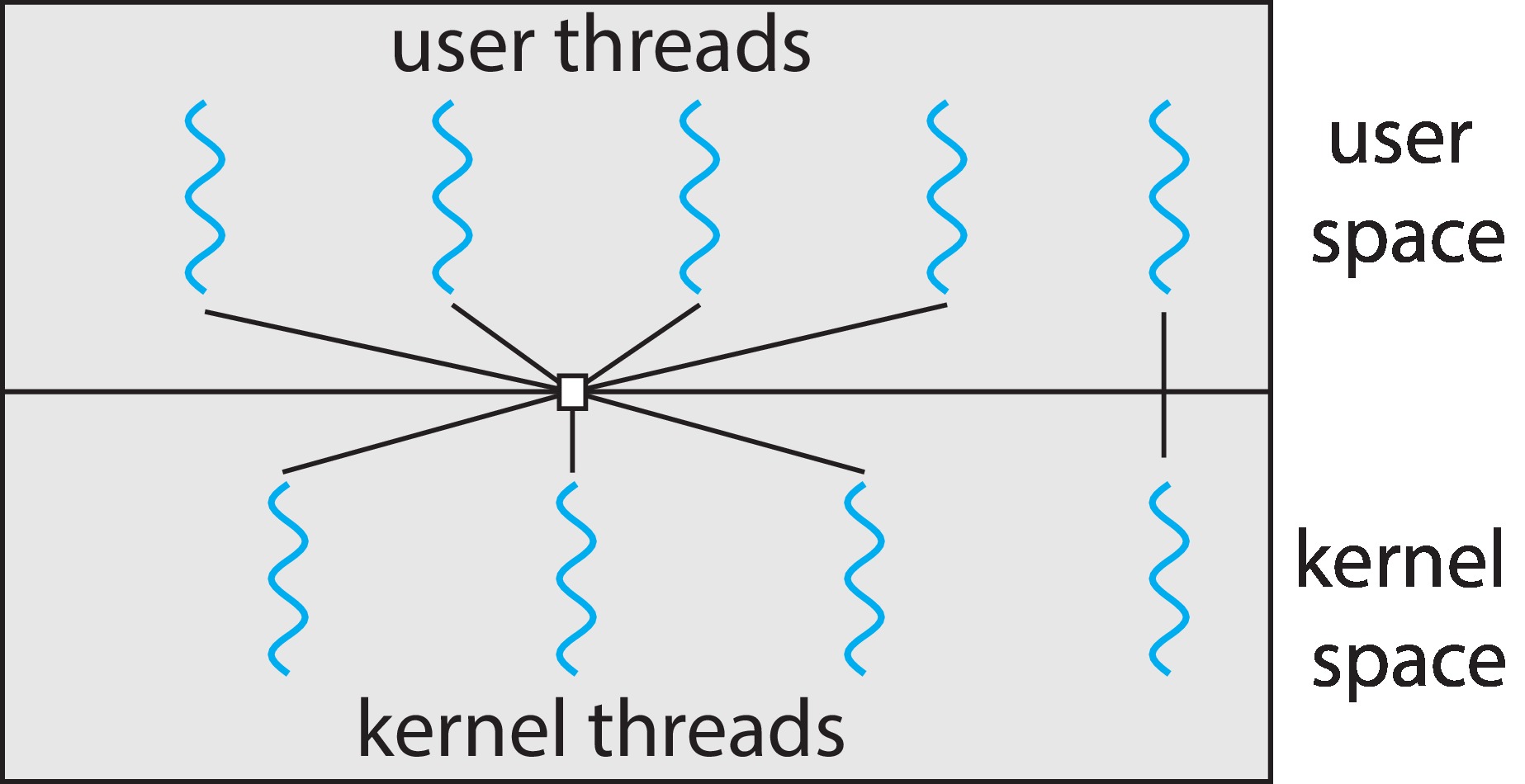
1.5.6 Scheduler Activations
我们已经了解了不同的线程模型,那么用户态线程库中创建的线程是如何变成可调度的内核线程的呢?对于多对多或两级线程模型的系统实现中,系统通常会假如一个中间层,叫LWP。对于用户线程库来说,LWP相当于一个虚拟的处理器,应用程序可以在其上调度用户线程运行。每个LWP都会附加到一个内核线程上,操作系统调度内核线程在物理处理器上运行。如果一个内核线程阻塞(例如等待I/O操作完成),LWP也会阻塞。紧接着,附加到LWP的用户级线程也会阻塞。
一个应用可能要好几个LWP才能确保程序的高效运行。假设一个在单处理器上运行的CPU密集型应用程序。在这种情况下,一次只能运行一个线程,因此一个LWP就足够了。然而,一个I/O密集型应用程序可能需要多个LWP来执行。即为每个并发阻塞的系统调用都需要一个LWP。例如,我们有五个不同的读文件请求,但我们只有四个LWP,那么第五个请求就必须等其中一个LWP从内核返回。
用于用户线程库和内核之间通信的方案称为调度激活。其工作原理如下:内核为应用程序提供一组虚拟处理器(LWP),应用程序可以将用户线程调度到可用的虚拟处理器上。此外,内核必须通知应用程序某些事件,这些事件被称为上行调用(Upcall)。上行调用由线程库通过上行调用处理程序处理,上行调用处理程序必须在虚拟处理器上运行。当用户线程即将被阻塞时,上行调用就会被触发,通知应用程序保存阻塞线程的状态,并调度其他线程运行。当阻塞事件结束时,内核再次触发上行调用,通知应用程序恢复之前阻塞的线程。
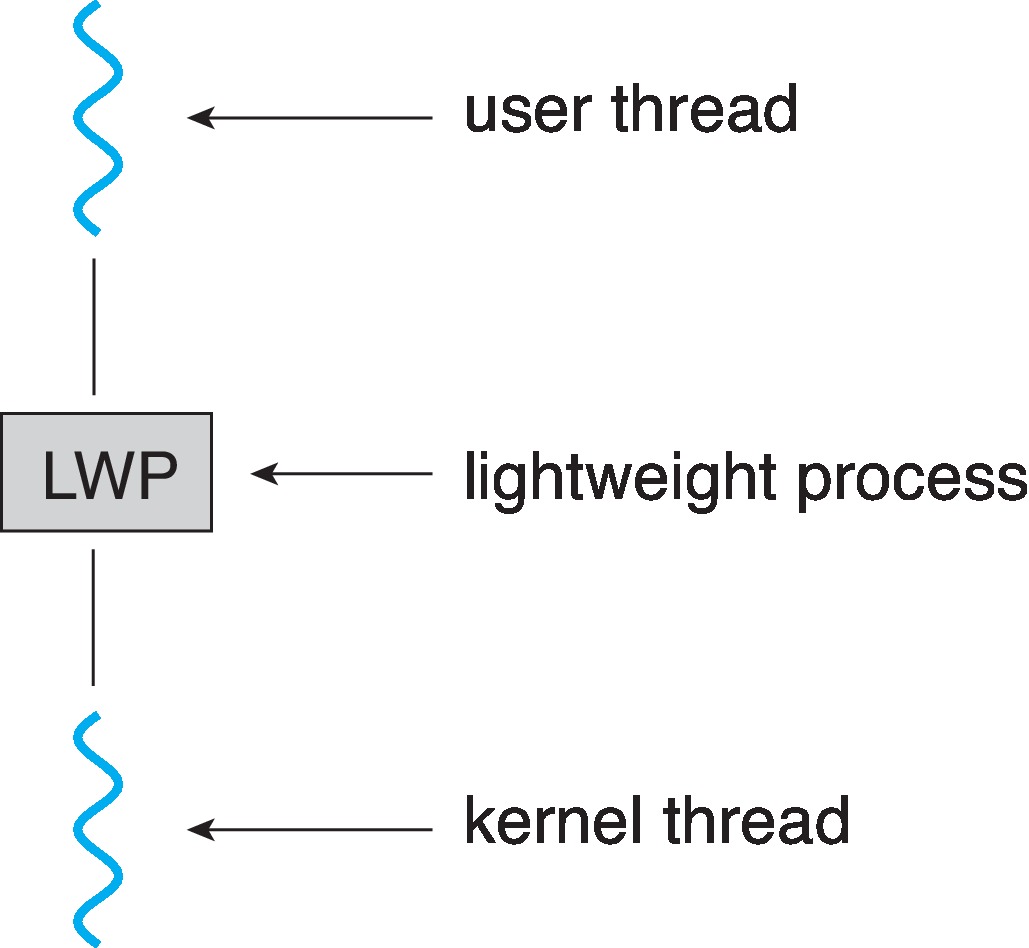
在一对一线程模型中,每个用户级线程对应一个内核级线程,因此不需要轻量级进程作为中间层。在这种模型中,用户级线程直接映射到内核级线程,操作系统内核负责调度和管理这些线程。
1.5.7 Different Thread Libraries
POSIX thread(pthread)区别于不同的系统实现,可以是用户级线程也可以是内核级线程;
Windows threads是内核级线程;
Java thread API会使用宿主机上的线程,宿主机上实现上面类型的线程,Java线程就是什么类型的;
1.6 Concurrency and Thread
到这里,我们已经了解过了进程,对线程也有了一定的理解。我们对比了进程和线程上下文切换开销。由于线程的轻量型,我们将线程作为CPU调度的基本单位,而进程作为资源管理的基本单位。
1.6.1 Concurrency
1.6.1.1 Time Sharing
要实现并发,系统就需要是分时的。分时系统将CPU时间分为一段一段的CPU时间片。我们通快速的切换任务。当时间片越来越小时,在宏观上用户和程序就会就会感觉像是独占了CPU。这就是分时的概念,程序在微观上交替执行,宏观上”同时“执行。

1.6.1.2 Different Concurrency
在现实中,我们有三种不同类型的并发:进程的并发、线程的并发和I/O复用。前两者是最好理解的,我们比较了进程和线程的优劣,对于进程的并发来说,每个进程都有自己独立的虚拟空间和资源,隔离性高,可以提供更好的安全性和稳定性;而进程切换的开销使得进程并发可能会影响系统资源。
线程的并发则减少了进程切换带来的系统开销,线程切换时仅仅保留执行时所需要的少量资源,其他的资源都由进程进行管理。而且线程减少了进程间通信的使用。然而,线程之间互相影响增加了并发控制的复杂性,稳定性相对差一点。
I/O复用我们将在学习完I/O系统后单独开一个阶段学习。I/O复用指的是多个I/O操作”同时“被单个进程/线程”同时“所处理,而不需要为每个I/O操作创建一个独立的进程/线程。常见的I/O复用技术有select、poll和epoll。
1.6.2 Parallelism
提到了并发,与之对应地,我们往往会想到并行的概念。并行我们很好理解,同时地做很多件事。初学者常会将这两个概念搞混,因为在宏观上,它们提供的效果太类似了。只要你的视角转向微观,你就会明白它们的不同。
并发是”同时“做多件事,但并行是同时做多件事。他们在宏观上好似都拥有同时,但在微观上只有并行是同时做的。并发关注结构,而并行关注执行,并发提供了解决问题的结构方法,可能支持并行化(多核),但也不必然(单核)。

1.6.3 Concurrency Unleashed: Redefining Multi-tasking
并发为我们带来许多优点,我们现在可以在单处理器上允许多个程序,实现微观上虽然是交替执行,但宏观上”并行“执行的特点。这种特性提升了CPU的利用率,从而带给我们更好的性能表现。
缺点同样显而易见,调度器需要瞻前顾后,增加了系统调度的复杂性,多个进程可能会相互作用,互相争夺资源,所以避免并发线程导致 inconsistent states 是我们需要关心的一大问题。除此之外,频繁调度所产生的上下文切换开销也是我们要关心的。
第二课 The POSIX Thread
POSIX 线程库提供了许多系统调用用于管理线程和线程属性。我们下面一步一步的来介绍这些系统调用。本阶段,我们着重于学习线程管理和线程属性相关的 POSIX 线程库中的系统调用。
2.1 The POSIX Thread: pthread API
pthread 是 POSIX 标准线程的缩写,它的标准定义在 IEEE 1003.1c 中,规范了 UNIX 系统中的线程行为。这些规范促成了代码在不同平台上(类 Unix)的可移植性。常用管理线程相关系统调用有:
#include <pthread.h>
pthread_create(); // Create a new thread
pthread_exit(); // Terminate the calling thread
pthread_join(); // Wait for a specific thread to exit
pthread_detach(); // Detach a thread
pthread_yield(); // Yield the processor to another thread
pthread_cancel(); // Send a cancellation request to a thread
pthread_testcancel(); // Test for pending cancellation requests
常用的线程属性相关的系统调用有:
#include <pthread.h>
pthread_attr_init(); // Initialize thread attributes object
pthread_attr_destroy(); // Destroy thread attributes object
pthread_attr_setdetachstate(); // Set the detach state attribute
pthread_attr_getdetachstate(); // Get the detach state attribute
pthread_attr_setstacksize(); // Set the stack size attribute
pthread_attr_getstacksize(); // Get the stack size attribute
pthread_attr_setstackaddr(); // Set the stack address attribute
pthread_attr_getstackaddr(); // Get the stack address attribute
pthread_attr_setscope(); // Set the contention scope attribute
pthread_attr_getscope(); // Get the contention scope attribute
pthread_attr_setschedparam(); // Set the scheduling parameters attribute
pthread_attr_getschedparam(); // Get the scheduling parameters attribute
2.2 pthread Management
我们先从管理 POSIX thread 的相关系统调用上学起。我们先来看线程创建的系统调用。
2.2.1 Create a POSIX Thread: pthread_create()
当要创建一个新的线程时,我们会用到pthread_create系统调用,其函数原型如下:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
/*
Parameters:
1. thread: Pointer to a pthread_t variable that will hold the thread ID.
2. attr: Pointer to a pthread_attr_t structure that specifies thread attributes (can be NULL for default attributes).
3. start_routine: Function pointer to the function to be executed by the thread.
4. arg: Argument to be passed to the start_routine function.
Return value: Returns 0 on success, non-zero on failure.
*/
这个函数有 4 个参数,需要接受一个 pthread_t 类型的线程类型变量、一个 pthread_attr_t 类型的线程属性、指向一个可调用对象的函数指针和需要传递的参数。本小节我们不需要关注第二个参数,线程属性是为了更小粒度的控制线程,我们留在下小节介绍。
2.2.1.1 Start Routine and New Calling Thread
在创建线程时,通过设置start_routine的函数指针,我们可以让创建好的线程去执行相关的start routine。在编写start_routine函数时,我们需要遵循以下规则:
void *(*start_routine) (void *)
/* Rules to obey:
Return value must be a (void*) pointer.
Parameter only can be one void* type pointer, can be a function pointer or else.
*/
下面展示如何使用pthread_create创建一个线程并打印 "Hello from thread!\\n" :
#include <stdio.h>
#include <pthread.h>
void* printHello(void* arg) { // This is a start routine
printf("Hello from thread!\n");
return NULL;
}
int main() {
pthread_t thread; // To store the thread ID
if (pthread_create(&thread, NULL, printHello, NULL) != 0) {
perror("Failed to create thread");
return 1;
}
if (pthread_join(thread, NULL) != 0) {
perror("Failed to join thread");
return 1;
}
printf("Hello from main!\n");
return 0;
}
当调用 pthread_create 后,新的线程将会创建并开始执行 start_routine 参数所指向的函数。创建完成之后,我们可以用pthread_t类型的变量来操作特定的线程。通过pthread_t变量,我们可以进行线程的管理和控制,比如调用pthread_join等操作来等待线程结束。
2.2.2 Join the Family: pthread_join()
当我们需要等待一个线程结束时,就会用到pthread_join()系统调用。pthread_join()会阻塞主线程(或其他线程)等待指定线程完成后再继续执行,它的函数原型如下:
int pthread_join(pthread_t thread, void **retval);
/*
Parameters:
1. thread: Thread ID of the thread to wait for.
2. retval: Pointer to a location where the thread's return value will be stored (can be NULL if not needed).
Return value: Returns 0 on success, non-zero on failure.
*/
为什么一个线程要等待另一个线程呢(主要是主线程等待子线程)?和我们前面学习过的进程 wait() 系统调用类似。主线程需要 pthread_join() 来读取返回值并回收子线程的资源。避免资源泄漏。
而且如果主线程没有等待子线程完成或者没有将子线程分离,主线程先行退出,那么所有未分离的子线程会被强制退出。这时,操作系统会强制性地回收子线程所占有的资源,可能导致数据完整性问题并带来同步问题。这里,你需要关心的问题是资源没有得到正确的释放。
2.2.3 Exit a Thread: pthread_exit()
线程有创建就有终止,当我们使用pthread_exit()系统调用时,线程就会终止执行并返回一个值给调用者。函数原型如下:
void pthread_exit(void *retval);
/*
Parameters:
1. retval: Pointer to the return value of the thread.
This function does not return.
*/
pthread_exit() 可以确保线程在退出时正确清理资源(pthread_cleanup_push),并将返回值传递给任何等待它的线程,例如通过 pthread_join() 函数等待的线程。
#include <pthread.h>
#include <stdio.h>
// Function to be executed by the thread
void* thread_function(void* arg) {
int *ret_val = (int*)malloc(sizeof(int));
*ret_val = 42; // Set the return value to 42
pthread_exit((void*)ret_val); // Exit the thread and return the value
}
int main() {
pthread_t thread;
int result;
void *retval;
// Create a new thread
result = pthread_create(&thread, NULL, thread_function, NULL);
if (result != 0) {
// Handle error
return -1;
}
// Wait for the specific thread to exit and get the return value
result = pthread_join(thread, &retval);
if (result != 0) {
// Handle error
return -1;
}
// Print the return value
printf("Thread returned value: %d\n", *(int*)retval);
// Free the allocated memory
free(retval);
return 0;
}
2.2.4 Detach from the Family: pthread_detach()
我们用pthread_detach 系统调用将线程设置为分离状态,使线程结束时资源能被自动回收。要设置守护线程等后台线程就需要将线程设置为分离状态。它的函数原型如下:
int pthread_detach(pthread_t thread);
/*
Parameters:
1. thread: Thread ID of the thread to detach.
Return value: Returns 0 on success, non-zero on failure.
*/
我们前面提到,主线程的退出会导致所有未分离线程的强制退出。而当线程被设置为分离状态后,主线程的退出就不会再影响分离后线程的运行了,这时分离的子线程会在后台继续运行,并在完成后由操作系统自动释放资源(当所有子线程完成后,操作系统会终止整个进程并回收资源)。
2.2.5 Yield a Thread Execution: pthread_yield()
当有需要让线程让出 CPU 给其他线程时,就会用到 pthread_yield 系统调用。需要注意的是,这个出让是系统层面上的。其函数原型如下:
int pthread_yield(void);
/* Explanation:
This function yields the processor to another thread.
Return value: Returns 0 on success, non-zero on failure.
*/
pthread_yield()会让线程主动放弃 CPU 。当线程调用pthread_yield()后,它将处于就绪状态,并让操作系统的调度程序选择运行其他就绪线程。一旦其他线程完成或被调度程序切换,原线程可以重新获得CPU时间并继续执行。
2.3 Attributes Control in POSIX thread
在前面,我们学习了线程会共享进程的地址空间、进程的一系列资源。但是要使得线程能够正常运行,线程还需要拥有自己独立的 TCB、寄存器组和栈空间。前面的两个由操作系统帮我们管理,作为程序员,你可以在创建子线程时规定一些线程的属性信息。包括:
- 栈大小(stack size):定义线程的栈大小空间,确保线程运行过程中不会发生栈溢出。你可以通过
pthread_attr_setstacksize函数设置栈大小。 - 调度参数(scheduling parameters):设置线程的优先级,以决定线程的执行顺序。可以通过
pthread_attr_setschedparam函数设置调度参数。 - 线程状态(thread state):可以设置线程是分离状态还是可连接状态。分离状态的线程在终止后会自动释放资源,而可连接状态的线程需要通过
pthread_join来回收资源。可以通过pthread_attr_setdetachstate函数设置线程状态。
2.3.1 Structure of Thread Attributes: thread_attr_t
在上小结 pthread_create() 中,我们见到了存放线程属性的结构 thread_attr_t 。所有关于线程属性的系统调用都是围绕着这个结构所展开的。简化版的结构体原型如下:
typedef struct {
int detachstate; // Thread detach state (PTHREAD_CREATE_JOINABLE or PTHREAD_CREATE_DETACHED)
int scope; // Contention scope (PTHREAD_SCOPE_SYSTEM or PTHREAD_SCOPE_PROCESS)
size_t stacksize; // Thread stack size
void *stackaddr; // Thread stack address
struct sched_param schedparam; // Scheduling parameters (priority, etc.)
// Other fields specific to the implementation
} pthread_attr_t;
下面是一个例子:
#include <pthread.h>
#include <stdio.h>
// Thread start routine
void* startRoutine(void* arg) {
// Thread work here
return NULL;
}
int main() {
pthread_attr_t attr;
pthread_t thread;
int result;
// Initialize the thread attributes object
pthread_attr_init(&attr);
// Specific settings for thread attributes
// Example: set the detach state
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
// Create a thread with the specified attributes
result = pthread_create(&thread, &attr, startRoutine, NULL);
if (result != 0) {
perror("Failed to create thread");
return 1;
}
/*
Do something here
*/
// Wait for the thread to terminate
result = pthread_join(thread, NULL);
if (result != 0) {
perror("Failed to join thread");
return 1;
}
// Destroy the thread attributes object
pthread_attr_destroy(&attr);
return 0;
}
2.3.2 Initialize the Structure:pthread_attr_init()
pthread_attr_init函数用于初始化一个线程属性对象,使其具有默认属性。初始化为默认属性有许多好处,我们希望避免未初始化属性导致的不确定行为,减少潜在的错误,提高查询的可靠性。pthread_attr_init系统调用完成后,我们就可以设置特定化一些的线程属性。
系统调用的原型如下:
int pthread_attr_init(pthread_attr_t *attr);
/*
Parameters:
1. attr: Pointer to a pthread_attr_t structure to be initialized.
Return value: Returns 0 on success, non-zero on failure.
*/
默认属性一般如下:
Thread attributes:
- Detach state = PTHREAD_CREATE_JOINABLE
- Scope = PTHREAD_SCOPE_SYSTEM
- Inherit scheduler = PTHREAD_INHERIT_SCHED
- Scheduling policy = SCHED_OTHER
- Scheduling priority = 0
- Guard size = 4096 bytes
- Stack address = 0x40196000
- Stack size = 0x201000 bytes
2.3.3 pthread_attr_destroy()
pthread_attr_destroy 用于销毁一个线程属性对象并释放其占用的资源。函数原型如下:
int pthread_attr_destroy(pthread_attr_t *attr);
/*
Parameters:
1. attr: Pointer to a pthread_attr_t structure to be destroyed.
Return value: Returns 0 on success, non-zero on failure.
*/
2.3.4 Setters and Getters
#include <pthread.h>
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. detachstate: Detach state to be set (PTHREAD_CREATE_JOINABLE or PTHREAD_CREATE_DETACHED).
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. detachstate: Pointer to an integer where the detach state will be stored.
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. stacksize: Stack size to be set.
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_getstacksize(const pthread_attr_t *attr, size_t *stacksize);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. stacksize: Pointer to a size_t where the stack size will be stored.
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_setstackaddr(pthread_attr_t *attr, void *stackaddr);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. stackaddr: Stack address to be set.
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_getstackaddr(const pthread_attr_t *attr, void **stackaddr);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. stackaddr: Pointer to a void* where the stack address will be stored.
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_setscope(pthread_attr_t *attr, int scope);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. scope: Contention scope to be set (PTHREAD_SCOPE_SYSTEM or PTHREAD_SCOPE_PROCESS).
Return value: Returns 0 on success, non-zero on failure.
*/
int pthread_attr_getscope(const pthread_attr_t *attr, int *scope);
/*
Parameters:
1. attr: Pointer to the thread attributes object.
2. scope: Pointer to an integer where the contention scope will be stored.
Return value: Returns 0 on success, non-zero on failure.
*/
2.4 Thread Cancellation
线程取消是一种机制,允许线程在完成其工作之前被另一个线程终止掉。其中,我们将要取消的线程叫做 target 。要取消某一线程,我们需要先用 pthread_cancel 发送取消请求给目标线程。之后,目标线程一般会在取消点检查取消请求,检查到取消请求后终止线程。(延迟取消)
线程可以设置自己的取消状态和取消类型,来决定如何相应取消请求。取消类型有:
- 异步取消(Asynchronous Cancellation):线程可以随时被取消。(风险较大)
- 延迟取消(Deferred Cancellation):线程在到达取消点时检查取消请求。
2.4.1 Setting Cancellation Type
线程可以使用 pthread_setcanceltype 系统调用来设置自己的取消类型
int pthread_setcanceltype(int type, int *oldtype);
/*
Parameters:
1. type: Specifies the new cancelability type for the thread. It can be one of the following:
- PTHREAD_CANCEL_DEFERRED: The thread will respond to cancellation requests at cancellation points (default).
- PTHREAD_CANCEL_ASYNCHRONOUS: The thread will respond to cancellation requests immediately.
2. oldtype: Pointer to an integer where the previous cancelability type will be stored. Can be NULL if the previous type is not needed.
Return value: Returns 0 on success, non-zero on failure.
*/
2.4.2 Cancel a Thread: pthread_cancel()
我们用 pthread_cancel 系统调用取消一个正在运行的线程。与 pthread_exit 不同的是, pthread_cancel 通常是其他线程调用。
int pthread_cancel(pthread_t thread);
/*
Parameters:
1. thread: Thread ID of the thread to be canceled.
Return value: Returns 0 on success, non-zero on failure.
*/
2.4.3 Create a Explicit Cancellation Point: pthread_testcancel()
pthread_testcancel 系统调用可以在调用线程中创建一个取消点,使线程能够响应取消请求。
void pthread_testcancel(void);
/*
Explanation: This function creates a cancellation point in the calling thread. If a cancellation request is pending, the thread will be canceled.
This function does not return a value.
*/
2.4.4 Implicit Cancellation Points
我们常常使用pthread_testcancel作为取消点来检查是否有取消请求,当检测到请求时,目标线程就会终止线程。然而,pthread 中的库函数还会作为潜在取消点(Potential Cancellation Points)。
潜在取消点指的是线程在执行这些操作时,可以检查并响应取消请求的地方。这些点通常是在系统调用或库函数内部,它们也会检查是否有取消请求,以确保线程能够及时响应取消请求。常见的潜在取消点有:
pthread_join:等待线程终止。如果在等待过程中收到取消请求,当前线程会响应并退出。pthread_testcancel:显式检查取消请求的位置。插入此调用可以设置明确的取消点。pthread_cond_wait:等待条件变量。如果在等待过程中收到取消请求,线程会响应取消。read和write:许多I/O操作,如文件读写,也会作为取消点。sleep:休眠函数在终止时也会检查取消请求。
2.4.5 Send Cancellation
我们主要使用 pthread_cancel 系统调用来发送取消请求,这是 POSIX 标准中提供的线程取消机制。通过 pthread_cancel ,可以发送取消请求并使目标线程在取消点检查和相应取消请求。下面是一个简单的例子:
#include <stdio.h>
#include <pthread.h>
void* startRoutine(void* arg) {
while (1) {
printf("Thread running\n");
pthread_testcancel(); // Set a cancellation point, check for cancel request
sleep(1);
}
pthread_exit(NULL);
}
int main() {
pthread_t thread;
pthread_create(&thread, NULL, startRoutine, NULL);
sleep(3); // Blocking for 3s before send cancellation.
pthread_cancel(thread); // Send cancellation.
pthread_join(thread, NULL);
printf("Main thread ends\n");
return 0;
}
2.4.6 Cleanup Handler
如果取消线程的时候线程仍然占有资源怎么办?为了避免资源泄漏,我们可以用下面的系统调用来设置一个 cleanup 句柄。确保每次线程取消时都会调用 cleanup routine 来清理线程,释放资源。
#include <pthread.h>
// Register cleanup handler with argument.
void pthread_cleanup_push(void (*routine)(void*), void *argument);
/*
1. routine: Pointer to the cleanup handler function.
2. argument: Argument to be passed to the cleanup handler function.
*/
// Run if execute is non-zero.
void pthread_cleanup_pop(int execute);
/*
1. execute: If non-zero, the cleanup handler is executed.
*/
注意,pthread_cleanup_push 和 pthread_cleanup_pop 必须在同一作用域下成对使用。如果使用了一个,就必须使用另一个。如果没有一个,那么两个都不要出现。
2.4.6.1 Cleanup Handler Example
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
void cleanupHandler(void *array) {
void** a = (void**) array;
if(*a != NULL){
free(*a);
printf("Array cleaned up.\n");
}
}
void* startRoutine(void* arg) {
int* array = (int*)malloc(sizeof(int) * 10); // 先分配内存
pthread_cleanup_push(cleanupHandler, (void*)&array);
while (1) {
printf("Thread running\n");
pthread_testcancel();
sleep(1);
}
pthread_cleanup_pop(1); // To pair
pthread_exit(NULL);
}
int main() {
pthread_t thread;
pthread_create(&thread, NULL, startRoutine, NULL);
sleep(3);
pthread_cancel(thread);
pthread_join(thread, NULL);
printf("Main thread ends\n");
return 0;
}
void** a = (void**) array;的必要性:使用(void**)提供了指针的间接访问,通过传递 void* 参数到清理函数,如果需要修改或检查传入的内存指针指向的内容,可以将其转换为 void**。通过类型转换确保指针类型匹配,使得我们能够访问并释放原指针指向的内存。
如果cancellation在pthread_cleanup_push(cleanupHandler, array);之前就发生了怎么办?我们可以用下面的方法:
int* array = NULL;
pthread_cleanup_push(cleanupHandler, &array);
array = (int*)malloc(sizeof(int) * 10);
第三课 Concurrency on Multicore System
3.1 Dark Age's Gone
在上一个阶段的结尾,我们简要讨论了多核处理器的调度问题。对于大多数系统来说,多核处理器和优化调度确实能够显著加快系统的运行速度。想象一下,如果有100个人在排队吃面条,显然两家面馆一起营业的效率会比只有一家面馆要高一倍。
3.1.1 Time Slicing on Unicore
3.1.2 Time Slicing on Multicore
3.2 Parallelism and Speedup
This depends on the nature of the task (n<core number and in an ideal scenario)
Fully parallelized: n*Threads = n*Speed
Partitally parallelized: n*Threads = N*Speed (1<N<n)
Cannot be parallelized: n*Threads = 1*Speed
3.3 Amdahl's Law
阿姆达尔定律(Amdahl's Law) 是计算机科学中的一个公式,用来预测系统在添加多个处理器后的最大可能加速比。阿姆达尔定律表达了一个程序中可以被并行化的部分和不能被并行化的部分,以及在添加更多处理器后系统性能的提升受限于那部分不可并行的计算。
3.3.1 Formula
x. Threads in Linux
x.1 线程和执行流
x.1.1 为什么用线程?
上述课程的学习完毕后,我们应当对线程有了一定了解了。简单来说,线程就是进程的执行流,执行流是什么我们马上会介绍。还记得我们进程番外篇学习的 IPC 机制么?通过IPC,我们创建多个进程共同解决一个问题,但这样做除了资源的浪费,还不得不考虑进程间通信带来的开销。但是引入线程后,上述两个我们最关系的问题迎刃而解。
在多核处理器的背景下,创建多个线程的好处是显而易见的——节省资源。线程虽然有独立的TCB,但是线程没有独立的进程虚拟地址空间。这就为线程带来很多相对进程而言的优点,这也是为什么线程能够打赢进程。当项目的代码量很大的时候,fork()创建的子进程的代码区会浪费很大一部分珍贵的内存空间,本质上还是父子进程共享”同一段“代码。但使用线程后,双引号就可以去掉了。
而且相比进程,线程为我们带来的优点有:
- 对线程的操作更快(创建、切换、销毁等);
- TCB 更轻量;
- 线程间数据直接共享,免去繁琐的 IPC 操作。
但是有优点就会有缺点,比如: - 因为进程之间彼此隔离,因而进程的稳定性更好。
x.1.2 栈空间的理解
在理解栈空间之前,我们可以先去看看进程代码是如何执行的——详见 《进程的一生——从出生到死亡 (Abandoned)》。知道了进程的执行逻辑之后,我们会注意到进程虚拟空间中 “栈” 这个名词的分量。栈是一个很重要的概念,代码的功能是在函数中执行的,而函数的执行依赖在栈空间中创造的一个个栈帧来实现。因此程序的执行和栈空间密不可分,即栈空间就是独立的运行上下文。
当一个进程拥有多个线程时,每个线程共享代码段、数据段等资源。每个线程创建的时候操作系统会为这个线程分配单独的栈空间资源。比如,一个线程的栈空间从A到B,另一个线程的栈空间从B到C(A<B<C),以此类推。每个线程的代码在各自的栈空间内运行。
我们可以用下面的代码来进行线程栈空间的初始化。
#include <thread>
#include <iostream>
void m_Func(){
}
int main(){
std::size_t stack_size = 1024*1024; // 1MB
std::thread t(std::thread(func), std::move(stack_size));
t.join();
return 0;
}
我们说线程之间数据共享,其实不仅仅是指数据段中的数据。理论上如果知道其他线程栈中局部变量在栈帧中的位置,也可以对这些数据进行操作。因此,线程中的资源是高度共享的。如果线程甲创建的栈帧覆盖线程乙的栈空间,就有可能导致进程的终止。(Threads share all segments except the stack, but a thread can still access the stack of another thread.)
x.2 Thread in Different System
在当下的日常生活中,无论是手机、电脑、工作站或是服务器都采用多核处理器架构。这是因为相比于执着地将单核登峰造极(在单核心上堆料),多加一个核心性价比要来的更好。由此,多核处理器成为了绝对的主流。但核心也不是越多越好的,要发挥多核处理器的性能优势,不仅仅需要操作系统合理的调度,同样也需要我们开发人员编写多线程的程序以供操作系统调度。
x.2.1 Thread Model in Windows
在Windows操作系统中,线程是进程的基本执行单元。每个进程可以包含一个或多个线程,这些线程共享进程的资源(如内存空间、文件句柄等)。当用户创建一个线程时,Windows会在内核中创建一个对应的内核级线程。Windows采用我们前面所说的1:1线程模型,即每个用户级线程对应一个内核级线程。这种模型的优点是线程管理和调度由操作系统内核负责,简化了开发者的工作。
在Windows中,同一台主机上,不同进程中的线程ID可能会重复,因为线程ID在进程内是唯一的。
x.2.2 Thread Model in Linux
在Linux操作系统中,线程和进程的概念则更加模糊。Linux使用轻量级进程(Lightweight Process, LWP)来实现线程,每个线程在内核中都是一个task。Linux通过pthread_create()或clone()系统调用创建线程,clone()允许创建一个共享资源的task(线程)。每个task都有一个唯一的struct task_struct数据结构,用于管理和调度。与Windows不同,Linux的线程模型更灵活,可以通过clone()的参数指定共享哪些资源。
在Linux中,所有属于同一进程的线程共享相同的线程组ID(TGID),这个TGID实际上就是进程的PID。而由于进程和线程都是为task,每个任务都有唯一的TID。所以同一台主机上的所有的线程ID都是唯一的。
x.3 Threads in Modern C++ : std::thread
C++11的多线程库提供了一组标准的API,用于创建和管理线程、同步线程操作等。这些API包括std::thread、std::mutex、std::condition_variable等。由于这些API是基于pthread标准设计的,因此它们在不同操作系统上的实现是相似的。
x.3.1 No OS Specific
Windows操作系统本身提供了丰富的线程API,如CreateThread、WaitForSingleObject等。C++11的多线程库在Windows上实现时,底层会调用这些Windows API。由于Windows采用1:1线程模型,因此每个C++创建的线程都会对应一个内核级线程。
Linux操作系统主要使用pthread库来实现多线程。C++11的多线程库在Linux上实现时,底层调用了pthread API,如pthread_create、pthread_join等。Linux的线程模型基于轻量级进程(LWP),C++程序中创建的每个线程都会对应一个task_struct。
x.3.2 Crate a Thread
当程序加载进内存,内核会创建该程序的主线程,其 start routine 的入口在 main() 的开始。在 main() 这个主线程下,我们可以使用 thread 类创建多个子线程。过程如下:
#include <iostream>
#include <thread>
static int i = 0;
void hello() {
i++;
std::cout << "Hello there! I am No." << i << std::endl;
}
int main() {
std::thread thread_1(hello);
std::thread thread_2(hello);
std::thread thread_3(hello);
std::thread thread_4(hello);
std::thread thread_5(hello);
std::thread thread_6(hello);
std::thread thread_7(hello);
std::thread thread_8(hello);
std::thread thread_9(hello);
std::thread thread_10(hello);
return 0;
}
通过thread类就可以创建线程类对象,我们需要给thread类的构造函数传递可调用对象的参数,这里使用函数作为参数。但这个程序会出现bug,这是因为:
- 主线程没有等待子线程而先行退出;
- 并没有实现对共享变量
i的互斥访问。
因而会导致如下的问题出现:
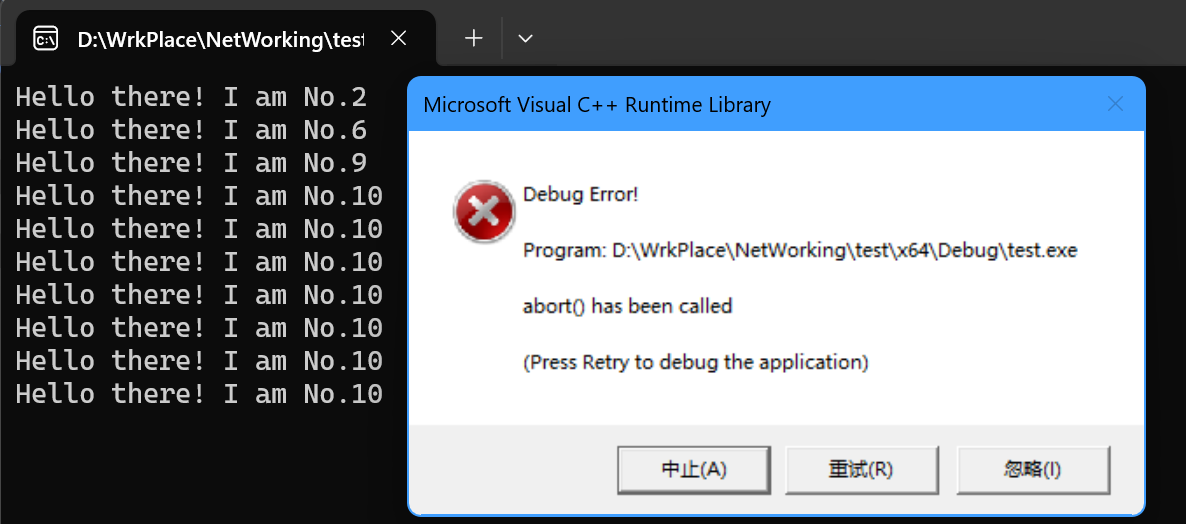
du@DVM:~/Desktop$ ./thread
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.6
terminate called without an active exception
Hello there! I am No.7
Aborted (core dumped)
x.3.2 Main Thread and Child Thread
程序执行对应着新进程的创建,在进程中,main函数就是主线程,而在主线程执行时,我们可以创建另外的线程,让这些线程并行独立执行。我们需要注意的是,如果主线程在子线程完成之前结束,程序会调用std::terminate,导致所有未完成的子线程被强制终止,从而引发abort()。
x.3.2.1 join()
为了避免主线程先于子线程结束,我们用join()函数来阻塞主线程等待子线程结束后再返回。join()确保主线程在子线程结束后回收其资源,避免资源泄漏。
#include <iostream>
#include <thread>
static int i = 0;
void hello() {
i++;
std::cout << "Hello there! I am No." << i << std::endl;
}
int main() {
std::thread thread_1(hello);
std::thread thread_2(hello);
std::thread thread_3(hello);
std::thread thread_4(hello);
std::thread thread_5(hello);
thread_1.join();
thread_2.join();
thread_3.join();
thread_4.join();
thread_5.join();
std::cout << "Main thread say byebye!" << std::endl;
return 0;
}
运行结果如下:
Hello there! I am No.2
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Main thread say byebye!
join()函数适用于需要确保子线程完成其任务后再继续主线程工作的情况。
x.3.2.2 detach()
另一种情况是我们想让子线程与主线程分离,主线程从此无法控制子线程,子线程被C++的运行库接管。主进程不需要等待子线程结束在退出,运行库会在这些子线程运行结束后自动清理资源。由此,detach()函数适用于不需要等待子线程完成的任务,例如后台任务或守护线程。
#include <iostream>
#include <thread>
static int i = 0;
void hello() {
i++;
std::cout << "Hello there! I am No." << i << std::endl;
}
int main() {
std::thread thread_1(hello);
std::thread thread_2(hello);
std::thread thread_3(hello);
std::thread thread_4(hello);
std::thread thread_5(hello);
thread_1.detach();
thread_2.detach();
thread_3.detach();
thread_4.detach();
thread_5.detach();
std::cout << "Main thread say byebye!" << std::endl;
return 0;
}
运行结果如下:
Main thread say byebye!
Hello there! I am No.1
我们看到主线程早早就结束了,有的子线程甚至还来不及在屏幕上向我们打招呼。
x.3.3 Thread Parameters Passing
有三种方式在在子线程中传递参数:1. 值传递;2. 引用传递;3. 指针传递。一般来说使用 detach() 函数时尽量不要传递指针,还不要使用隐式类型转换。
x.3.3.1 Pass by Value
普通类型在传递子线程函数参数时,我们可以直接使用值传递。当我们使用值传递时,函数收到的是变量的副本,也就是说,函数内部的变量和元素的变量是两个独立的变量了,修改函数内部的变量并不会影响到原始的变量。所以,当使用值传递时,主线程可以放心的退出。
x.3.3.2 Pass by Reference
在C++的 std::thread 中,直接传递引用参数需要使用 std::ref 来包装引用,否则 std::thread 会尝试复制参数,这会导致编译错误或未定义行为。示例如下:
#include <iostream>
#include <thread>
void hello(int& i) {
//void hello(const int i){
i++;
std::cout << "Hello there! I am No." << i << std::endl;
}
int main() {
int i = 0;
std::thread thread_1(hello, std::ref(i));
// std::thread thread_1(hello, i);
thread_1.join();
std::cout << "Main thread: i = " << i << std::endl;
return 0;
}
使用普通的引用传递会调用一次复制构造函数,导致函数无法对引用对象进行修改,于是我们有std::ref,它可以使子线程在传递参数时不再调用复制构造函数。
x.3.3.3 Pass by Pointer
每个函数的调用和返回都是伴随着栈内存中栈帧的创建和销毁。如果函数内申请了一段堆内存空间,我们就需要在函数返回之前(栈帧销毁前)将这段堆内存给释放掉,因为栈内存是堆内存的唯一寻址方式。所以,当主线程退出而子线程仍在运行且访问传递的指针时,就可能会导致指针悬挂的问题(因为内存已经释放掉了)。
再者,多个线程同时访问指针指向的数据。期间若是涉及到了数据的写操作,我们还不得不考虑数据一致性的问题,可能需要额外的同步机制来确保数据的安全问题。
在现代C++中,我们可以使用智能指针来避免内存释放的问题,但是数据一致性还是我们需要考虑的。下面是使用std::shared_ptr的示例,即使主线程退出,我们仍然可以正确管理内存。
#include <iostream>
#include <thread>
#include <memory>
#include <chrono>
void hello(std::shared_ptr<int> ptr) {
(*ptr)++;
std::cout << "Hello there! I am No." << *ptr << std::endl;
}
int main() {
auto ptr = std::make_shared<int>(0);
std::thread thread_1(hello, ptr);
std::thread thread_2(hello, ptr);
std::thread thread_3(hello, ptr);
std::thread thread_4(hello, ptr);
std::thread thread_5(hello, ptr);
thread_1.detach();
thread_2.detach();
thread_3.detach();
thread_4.detach();
thread_5.detach();
std::this_thread::sleep_for(std::chrono::seconds(2)); // 确保子线程有时间完成
std::cout << "Main thread say byebye!" << std::endl;
return 0;
}
运行结果如下:
Hello there! I am No.2
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Main thread say byebye!
x.3.4 Problem Caused by Condition Race
你可能已经注意到,我们上面代码的运行结果并不符合我们所想象的那样。虽然我们用join()确保子线程运行完成,但是我们仍然看到这种情况:
Hello there! I am No.2
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Hello there! I am No.5
Main thread say byebye!
这是由于操作系统的线程调度机制和竞态条件导致的。线程的执行顺序由操作系统的调度器决定,可能导致输出顺序的不确定性。为了解决这种问题,我们可以使用同步机制,如互斥锁(mutex) 或 条件变量(condition variable),也可以将操作原子化(atomic operation)。我们将在下一阶段介绍这些技术。
第y课 Co-routine(C++20)
协程本身并不作为操作系统中的内容。协程是用户级的并发编程模型。这里仅作为补充。协程并不算新鲜词,Melvin Conway在1958年就提出了协程的概念,并应用于汇编程序中。
协程并不算是操作系统的内容,因为它是在用户态实现的。引入协程的概念就是为了避免线程切换的开销,作为更小型的并发控制流,协程随即应运而生。因为协程是用户级别的并发编程模型,所以协程切换时不需要从用户态陷入内核态,系统内核对协程的存在也一无所知。
在本阶段,我们提到了内核调度的最小单位是内核级的线程。现代的操作系统中,一个用户级线程往往对应着一个内核级线程,当我们在用户空间创建一个用户空间线程之后,我们可以说我们创建了一个内核可以调用的真•线程。而协程往往在一个线程中运行,所以协程并不提高程序的性能。
y.1 Function vs. Coroutine
协程和函数很类似,你可以说协程就是一个能暂停并继续执行的函数。当函数中出现co_await、co_yield或co_return的其中一项时,该函数就可被看作为一个协程。下图展示了函数和协程的调用过程。当函数被调用时,函数就会开始执行,直到遇到return或到达函数末尾。而协程可以执行一部分程序后挂起,等待再次调度。协程实现了在单个线程内的并发执行。

由于协程在用户空间实现并发,我们可以控制代码的执行顺序,从而减少多任务调度造成的竞争问题(特别是cooperative multitasking)。由于协程在单个线程内运行,并且可以在执行过程中暂停和恢复,因此我们可以避免传统多线程编程中常见的竞争条件和锁定问题。在某些情况下,仍然需要使用同步机制来确保一致性。
y.2 Coroutine Frame and Coroutine Keywords
y.2.1 Coroutine Frame
为了实现协程从挂起恢复后继续运行,协程也需要保存上下文状态信息,这些上下文状态信息被存放在coroutine frame中。根据coroutine frame的实现方式,我们有两类协程:stackfull coroutine和stackless coroutine(C++20 使用的是 stackless coroutine)。Stackfull coroutine会将coroutine的数据和c-routine frame存放在stack中,而stackless coroutine的实现方式则会把coroutine存放在堆上。
这些上下文信息会有编译器代为我们管理。当协程的生命周期结束时,协程帧就会被销毁。
y.2.2 Coroutine Keywords
在C++中,我们有三个关键字:co_await、co_yield和co_return。这三个关键字得以让协程与外界进行交互。协程可以被暂停/挂起和恢复执行。其中,co_await和co_yield可以挂起协程,而co_return用于返回。它们有不同的行为,协程状态与这三个关键字也息息相关。
y.3 Coroutine Return Type
包含协程三个关键字之一的函数就可以被看作是一个协程。但需要注意的是,在C++中,当我们创建协程时,协程的返回类型必须是一个特定的类型,该类型需要包含一个名为promise_type的嵌套类型(和std::promise没关系)。所以下面返回类型为int的协程代码在编译时就会报错:
int foo() {std::suspend_always{};}
promise_type是一个类对象(struct或class,而且必须名为promise_type),定义并控制协程的行为和生命周期管理。返回值类型就是对这个promise_type的包装,如下:
struct co_return {
struct promise_type {
// Something needs to be done here...
};
};
co_return foo() {}
y.3.1 Elements in promise_type
在promise_type中,需要至少包含以下的方法get_return_object、initial_suspend、final_suspend、return_void(或return_value)和unhandled_exception。我们将一步一步的对这五个方法进行说明。最小的协程返回对象如下:
struct co_return {
struct promise_type {
co_return get_return_object() { return {}; }
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() { std::terminate(); }
};
};
y.3.1.1 get_return_object
这是最先开始执行的方法,get_return_object方法构造协程的返回类型(这里是co_return)并返回promise_type的父类型,也就是协程的返回类型。这里的return {};表示返回默认构造的co_return。
y.3.1.2 initial_suspend
这个方法在协程开始执行之前被调用,返回一个可等待对象,决定协程是否在开始时挂起。这里,返回的可等待对象可以是std::suspend_never或std::suspend_always。我们这里使用前者,表示协程在开始时不会挂起,而是立即执行。return {};返回默认构造的std::suspend_never。
根据不同的启动方式,协程可以被分为Lazily started coroutines和eagerly started coroutines。我们例子中给出的是eagerly started coroutines,这些协程在创建时就会立即开始执行。如果我们在这里返回的可等待对象是std::suspend_always那么我们就会创建lazily started coroutine。
y.3.1.3 final_suspend
与 initial_suspend 类似,final_suspend 方法在协程结束时被调用,它同样返回一个可等待对象,决定协程是否在结束时挂起。这里我们使用 std::suspend_never 。 final_suspend 是一个 non-throwing method,这就是为什么通常使用 noexcept 关键字。
y.3.1.4 return_void or return_value
这两个方法用于处理协程的返回值。如果协程没有返回值,则使用return_void;如果协程返回值,则使用return_value。在例子中,我们不设置任何返回值,所以使用return_void。
y.3.1.5 unhandled_exception
unhandled_exception 方法用于协程中的异常处理,在协程中抛出未捕获的异常时被调用。在一些的例子中,我们不需要做任何的异常处理。例子中,我们使用 std::terminate() 来终止协程。
y.3.2 Trivial Awaiters
C++标准提供了两个常见的 awaiters,std::suspend_always 和 std::suspend_never。当使用 std::suspend_always 时,,协程会在遇到 co_await 时立即挂起。使用 std::suspend_never 时,协程会在遇到 co_await 时继续执行,不会挂起。
y.4 Executing Coroutine and Resuming Coroutine
y.4.1 Executing a Coroutine
#include <iostream>
#include <coroutine>
struct co_return {
struct promise_type {
co_return get_return_object() { return {}; }
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() { std::terminate(); }
};
};
co_return coroutine_foo() {
std::cout << "Hello ";
co_await std::suspend_always{};
std::cout << "world!" << std::endl;
}
int main() {
co_return cofoo = coroutine_foo();
cofoo();
return 0;
}
y.4.2 Resuming Coroutine
#include <iostream>
#include <coroutine>
struct co_return {
struct promise_type {
co_return get_return_object() { return co_return{std::coroutine_handle<promise_type>::form_promise(*this)}; }
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() { std::terminate(); }
};
std::coroutine_handle<> handle;
co_return(std::coroutine_handle<> handle_): handle{handle_}{ }
operator std::coroutine_handle<promise_type>() const {return handle_}
};
co_return coroutine_foo() {
std::cout << "1. Hello! \n";
co_await std::suspend_always{};
std::cout << "2. Again! \n";
co_awiat std::suspend_always{};
std::cout << "3. Another Hello! \n";
co_awiat std::suspend_always{};
std::cout << "4. Another another Hello! \n";
}
int main() {
co_return cofoo = coroutine_foo();
cofoo.handle.resume();
cofoo.handle(); // Calls std::coroutine_handle<>::operator();
std::cout << std::boolalpha << cofoo.handle.done() << std::endl; // Check if coroutine is executed.
cofoo();
return 0;
}
学不明白。。。课程链接如下: